|
I am Director at the Barcelona Supercomputing Center (BSC), one of Europe’s largest research centers and home to the MareNostrum supercomputer, leading over 1,400 researchers advancing science through AI and HPC. Erdős number: 3. LinkedIn / Threads / Twitter / Google Scholar / Email |

|
|
I'm interested in computer vision, machine learning, security in AI, adversarial attacks and fairness. |
 |
Maya Pavlova, Erik Brinkman, Krithika Iyer, Vitor Albiero, Joanna Bitton, Hailey Nguyen, Joe Li, Cristian Canton Ferrer, Ivan Evtimov, Aaron Grattafiori International Conference on Learning Representations (ICLR), Singapore, 2024. [bibtex] TL;DR. Meet GOAT (Generative Offensive Agent Tester), an automatic red teaming system to simulate adversarial conversations and identify vulnerabilities in large language models (LLMs). It uses a range of adversarial prompting techniques to test the limits of LLMs, automating the red teaming process to make it more efficient and effective. |
 |
Cristian Canton Ferrer + a long list of co-authors Meta AI Technical Report, 2024. [bibtex] TL;DR. A collection of open source multi-modal multi-lingual GenAI models (7B, 70B, 405B) with SOTA capabilities. Among my contributions, to make it safe and robust via red teaming. |
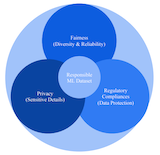 |
Surbhi Mittal, Kartik Thakral, Richa Singh, Mayank Vatsa, Tamar Glaser, Cristian Canton Ferrer, Tal Hassner Nature Machine Intelligence, 2024. [bibtex] TL;DR. A summary paper evaluating fairness, privacy and regulatory aspects of over 100 datasets. A work that sets the standards on defining what a responsible dataset is. |
 |
Yi Zeng, Xuelin Yang, Li Chen, Cristian Canton Ferrer, Ming Jin, Michael I. Jordan, Ruoxi Jia NeurIPS, 2024. [bibtex] TL;DR. This paper proposes a meta-learning framework for group-level fairness in machine learning, which incorporates a multi-player cooperative bargaining game to resolve hypergradient conflicts that may arise when fairness objectives are integrated into the model training process. |
 |
Christophe Ropers, David Dale, Prangthip Hansanti, Gabriel Mejia Gonzalez, Ivan Evtimov, Corinne Wong, Christophe Touret, Kristina Pereyra, Seohyun Sonia Kim, Cristian Canton Ferrer, Pierre Andrews, Marta R. Costa-jussà ACL, 2024. [bibtex] TL;DR. This paper presents the first study on human based red teaming for Machine Translation,marking a significant step towards understanding and improving the performance of translation models. |
 |
Maxim Maximov, Tim Meinhardt, Ismail Elezi, Zoe Papakipos, Caner Hazirbas, Cristian Canton Ferrer, Laura Leal-Taixé IEEE International Conference on Automatic Face and Gesture Recognition, Istanbul (Turkey), 2024. [bibtex] TL;DR. In this paper we prove that the pedestrian tracking task can be done in a privacy preserving manner by replacing individuals by time-consistent full-body person synthetic. |
 |
Baptiste Rozière, Jonas Gehring, ..., Cristian Canton Ferrer, and many more amazing authors. Meta AI Technical Report, 2023. [bibtex] [GitHub] [Model] TL;DR. Code Llama is an AI model built on top of Llama 2, fine-tuned for generating and discussing code. First of it kind! |
 |
Hugo Touvron, Louis Martin, ..., Cristian Canton Ferrer, and many more amazing authors. Meta AI Technical Report, 2023. [bibtex] [dataset] TL;DR. This paper introduces Llama2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. |
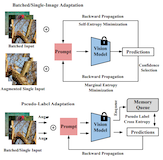 |
Jiachen Sun, Mark Ibrahim, Melissa Hall, Ivan Evtimov, Zhuoqing Mao, Cristian Canton Ferrer, Caner Hazirbas ACM International Conference on Multimedia (ACM MM), Ottawa (Canada), 2023. [bibtex] TL;DR. The first framework that generalizes visual prompting with test-time adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information. |
 |
Bilal Porgali, Vítor Albiero, Jordan Ryda, Cristian Canton Ferrer, Caner Hazirbas Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Fair, Data-efficient, and Trusted Computer Vision, Vancouver (Canada), 2023. [bibtex] TL;DR. A diverse, large benchmark for measuring fairness and robustness in audio/vision/speech models. A bold step forward from our Casual Conversations v1 dataset. |
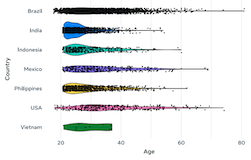 |
Caner Hazirbas, Yejin Bang, Tiezheng Yu, Parisa Assar, Bilal Porgali, Vítor Albiero, Stefan Hermanek, Jacqueline Pan, Emily McReynolds, Miranda Bogen, Pascale Fung, Cristian Canton Ferrer Meta AI Report, 2023. [bibtex] TL;DR. A walk through on how to design a dataset that is useful to measure gaps in bias and robustness for computer vision and speech. |
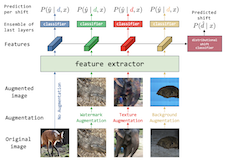 |
Zhiheng Li, Ivan Evtimov, Albert Gordo, Caner Hazirbas, Tal Hassner, Cristian Canton Ferrer, Chenliang Xu, Mark Ibrahim Computer Vision and Pattern Recognition Conference (CVPR), Vancouver (Canada), 2023. [bibtex] TL;DR. Unintended decision rules that are unable to generalize, shortcuts, are very prevalent in ML models. This paper how mitigations for shortcuts are a whack-a-model game, for now. |
 |
Jane Dwivedi-Yu, Yi-Chia Wang, Lijing Qin, Cristian Canton, Alon Y. Halevy ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Washington DC, (USA), 2022. [bibtex] TL;DR. A first paper to design a ranking function that gives useful and personalized post recommendations in social media. |
 |
Vikash Sehwag, Caner Hazirbas, Albert Gordo, Firat Ozgenel, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, (USA), 2022. [bibtex] TL;DR. Leverage diffusion process based generative models to synthesize novel images from low-density regions. |
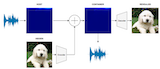 |
Margarita Geleta, Cristina Punti, Kevin McGuinness, Jordi Pons, Cristian Canton, Xavier Giro-i-Nieto IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 2022. [bibtex] TL;DR. A pioneering work on hidding images on audio, showing real results retrieving images from recorded audio waves. |
 |
Zoe Papakipos, Giorgos Tolias, Tomas Jenicek, Ed Pizzi, Shuhei Yokoo, Wenhao Wang, Yifan Sun, Weipu Zhang, Yi Yang, Sanjay Addicam, Sergio Manuel Papadakis, Cristian Canton, Ondrej Chum, Matthijs Douze NeurIPS Workshop Summary, 2021. [bibtex] TL;DR. A quantitative and qualitative analysis of the top submissions to the 2021 Image Similarity Challenge. |
 |
Matthijs Douze, Giorgos Tolias, Ed Pizzi, Zoë Papakipos, Lowik Chanussot, Filip Radenovic, Tomas Jenicek, Maxim Maximov, Laura Leal-Taixé, Ismail Elezi, Ondřej Chum, Cristian Canton Facebook AI Technical Report, 2021. [bibtex] [Competition Track 1] [Competition Track 2] TL;DR. Prove how good are you at finding modified copies of images. $200K in prizes! |
 |
Ivan Evtimov, Russ Howes, Brian Dolhansky, Hamed Firooz, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Adversarial Machine Learning, 2021. Best paper award [bibtex] TL;DR. Multimodal understanding (image+text) can be attacked in a gray-box fashing. Examples on hate memes included! |
 |
Ousmane Dia, Theofanis Karaletsos, Caner Hazirbas, Cristian Canton, Ilknur Kaynar Kabul, Erik Meijer Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Adversarial Machine Learning, 2021. [bibtex] TL;DR. Undertand what areas of an image are more vulnerable to increase uncertainty of models and eventually making them to produce wrong decisions. |
 |
Brian Dolhansky, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Adversarial Machine Learning, 2021. [bibtex] TL;DR. Hashing algorithms (in general) can be easily compromised by introducing collisions. |
 |
Caner Hazirbas, Joanna Bitton, Brian Dolhansky, Jacqueline Pan, Albert Gordo, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Responsible Computer Vision, 2021. IEEE Transactions on Biometrics, Behavior, and Identity Science (TBIOM), 2021. [bibtex] [dataset] TL;DR. A large dataset (10TB, 30+ days of video, 3K people, 15 mins per person) featuring a diversity of actors with age, gender and skin tone annotations. |
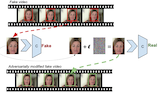 |
Shehzeen Hussain, Paarth Neekhara, Brian Dolhansky, Joanna Bitton, Cristian Canton, Julian McAuley, Farinaz Koushanfar Journal - ACM Digital Threats: Research and Practice, 2021. [bibtex] TL;DR. Defusing deepfake detection by crafting universal adversarial perturbations, transferable across different detection models. |
 |
Paarth Neekhara, Brian Dolhansky, Joanna Bitton, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR). Workshop on Media Forensics, 2021. [bibtex] TL;DR. Creation of adversarial additive patterns against open sourced deepfake detection systems turns out to be very effective. |
 |
Hao Guo, Brian Dolhansky, Eric Hsin, Phong Dinh, Song Wang, Cristian Canton IEEE Winter Conference on Applications of Computer Vision (WACV), 2021. [bibtex] TL;DR. Create embeddings that are privacy preserving thus non-reversible to obtain the original image. |
 |
Alon Halevy, Cristian Canton, Hao Ma, Umut Ozertem, Patrick Pantel, Marzieh Saeidi, Fabrizio Silvestri, Ves Stoyanov Journal - Communications of the ACM (CACM), 2021. [bibtex] TL;DR. A comprehensive survey of AI techniques applied in social networks to preserve integrity and preserve users from bad experiences. |
 |
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, Cristian Canton Facebook AI Technical Report, 2020. [bibtex] [dataset] [Kaggle competition] TL;DR. Up to today, the largest deepfake dataset. A $1M competition! |
 |
Brian Dolhansky, Russ Howes, Ben Pflaum, Nicole Baram, Cristian Canton Facebook AI Technical Report, 2019. [bibtex] [dataset] [blog post] TL;DR. A small preview version of the DFDC dataset to come later. |
 |
Benet Oriol Sabat, Cristian Canton, Xavier Giró‑i‑Nieto NeurIPS AI for Social Good Workshop, Vancouver, (Canada), 2019. [bibtex] TL;DR. Multimodal understanding of memes can allow better detection of image+text hate speech. |
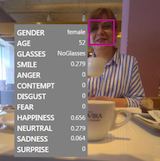 |
Maedeh Aghaei, Mariella Dimiccoli, Cristian Canton, Petia Radeva Journal - Computer Vision and Image Understanding (CVIU), 2018. [bibtex] TL;DR. Leverage ego-centric camera footage to understand long time span scene interactions, specially for social style signals.. |
 |
Brian Dolhansky, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, (USA), 2018. [bibtex] [poster] TL;DR. Given an example of how your eyes look, this algorithm can take a pic with your eyes closed and open them. GAN-powered. |
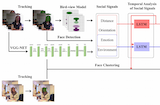 |
Maedeh Aghaei, Mariella Dimiccoli, Cristian Canton, Petia Radeva International Conference on Computer Vision (ICCV). Workshop on Egocentric Percetion, Interaction and Computing, Venice (Italy), 2017. [bibtex] TL;DR. Use an ego-camera, process multimodal inputs to do long time span scene understanding, specially for social style signals. |
 |
Xunyu Lin, Víctor Campos, Xavier Giró‑i‑Nieto, Jordi Torres, Cristian Canton Computer Vision and Pattern Recognition Conference (CVPR). Brave New Motion Representations Workshop, Honolulu (USA), 2017. [bibtex] [source code] [poster] TL;DR. An unsupervised framework to extract semantically rich features for video representation inspired by how the human visual system groups objects based on motion cues. |
 |
Junting Pan, Cristian Canton, Kevin McGuinness, Noel O'Connor, Jordi Torres, Elisa Sayrol, Xavier Giró‑i‑Nieto Computer Vision and Pattern Recognition Conference (CVPR). Scene Understanding Workshop, Honolulu (USA), 2017. [bibtex] [source code] [poster] TL;DR. Estimate of saliency using a GAN, probably the first article to do it! |
 |
Emad Barsoum, Cha Zhang, Cristian Canton, Zhengyou Zhang ACM International Conference on Multimodal Interaction (ICMI), Tokio (Japan), 2016. [bibtex] [dataset] TL;DR. Some strategies to combine multiple subjective labels for human emotions in a way that CNNs can be trained effectively. |
 |
Sarah Bargal, Emad Barsoum, Cristian Canton, Cha Zhang ACM International Conference on Multimodal Interaction (ICMI). Workshop on Facial Expressions in the Wild, Tokio (Japan), 2016. [bibtex] TL;DR. Ensambles of CNN embeddings allow for high accuracy emotion recognition on videos. |
 |
Laura Leal-Taixé, Cristian Canton, Konrad Schindler Computer Vision and Pattern Recognition Conference (CVPR). DeepVision Workshop, Las Vegas (USA), 2016. [bibtex] [poster] TL;DR. While tracking multiple targets, comparing detections using a Siamese network improves overall performance. |
|
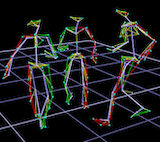
Cristian Canton, P. Smyth Book chapter - Skill Training in Multimodal Virtual Environments (Taylor & Francis Ed.), 2012. [bibtex] TL;DR. A survey on marker based motion capture technologies for pose estimation. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs, Enric Monte Journal - EURASIP Journal on Advances on Signal Processing, 2011. [bibtex] TL;DR. Tracking multiple object on the 3D domain by voxel reconstruction and particle filtering techniques. |
|
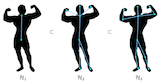
Cristian Canton, Josep R. Casas, Montse Pardàs Journal - Computer Vision and Image Understanding (CVIU), 2011. [bibtex] TL;DR. A new Monte Carlo method applied to recover articulated structured (human body) exploiting hierarchies of complexity. |

|
Taras Butko, Cristian Canton, Carlos Segura, Xavier Giró-i-Nieto, Climent Nadeu, Javier Hernando, Josep R. Casas Journal - EURASIP Journal on Advances on Signal Processing, 2011. [bibtex] TL;DR. Combination of motion cues, position and audio allows detection of events within a SmartRoom environment. |

|
Montse Pardàs, Verónica Vilaplana, Cristian Canton Book chapter - Multimodal Signal Processing: Theory and applications for human-computer interaction (Academic Press), 2010. [bibtex] TL;DR. Survey on image and video processing techniques for human computer interaction in SmartRooms. |
|
Adolfo López, Cristian Canton, Josep R. Casas, European Signal Processing Conference (EUSIPCO), Aalborg (Denmark), 2010. [bibtex] TL;DR. Generating virtual orthogonal views derived from 3D voxels allow better action recognition on 2D projections. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs Journal - EURASIP Journal on Advances on Signal Processing, 2010. [bibtex] TL;DR. Marker based motion tracking using annealed particle filtering. |
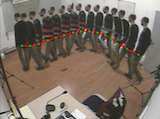
|
Cristian Canton, Josep R. Casas, Montse Pardàs IEEE International Computer Vision and Pattern Recognition Conference (CVPR). Biometrics Workshop, San Francisco (USA), 2010. [bibtex] TL;DR. Understanding actions directly on 3D+time hypervolumes using the Radon transform. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs IEEE International Computer Vision and Pattern Recognition Conference (CVPR). Computer Vision for Games Workshop, San Francisco (USA), 2010. [bibtex] TL;DR. Conditioning particle filtering to run on surface of volumes ensure better tracking through a new occupancy resampling strategy. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs, Enric Monte Technical Report - Technical University of Catalonia, 2009. [bibtex] TL;DR. An approach to a fair estimation of human pose estimation through the Kolmogorov-Smirnov test. |
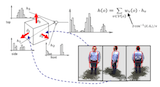
|
Michael Voit, Nicolas Gourier, Cristian Canton, Oswald Lanz, Rainer Stiefelhagen, Roberto Brunelli Book chapter - Computers in the Human Interaction Loop (Springer-Verlag), 2009. [bibtex] TL;DR. A survey of the technologies for head pose estimation in multimodal environments. |

|
Kai Nickel, Montse Pardàs, Rainer Stiefelhagen, Cristian Canton, José Luis Landabaso, Josep R. Casas Book chapter - Computers in the Human Interaction Loop (Springer-Verlag), 2009. [bibtex] TL;DR. A survey on activity recognition technologies applied to SmartRooms. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs IEEE International Conference on Image Processing (ICIP), Cairo (Egypt), 2009. [bibtex] [poster] TL;DR. Marker based motion tracking using annealed particle filtering. |
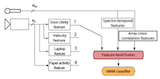
|
Taras Butko, Cristian Canton, Carlos Segura, Xavier Giró-i-Nieto, Climent Nadeu, Javier Hernando, Josep R. Casas Interspeech, Brighton (UK), 2009. [bibtex] TL;DR. Acoustic event detection using multiple cues and specific features using HMM. |

|
Cristian Canton, Taras Butko, Carlos Segura, Xavier Giró-i-Nieto, Climent Nadeu, Javier Hernando, Josep R. Casas IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). Human Communicative Behavior Analysis Workshop, Miami (USA), 2009. [bibtex] [poster] TL;DR. Combination of motion cues, position and audio allows detection of events within a SmartRoom environment. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs IEEE Conference on 3DTV, Postdam (Germany), 2009. [bibtex] TL;DR. Markerless human body capture leveraging annealed particle filters prove to be effective and robust to occlusions. |

|
Cristian Canton, Rosella Sblendido, Josep R. Casas, Montse Pardàs IEEE International Conference on Image Processing (ICIP), San Diego (USA), 2008. [bibtex] [poster] TL;DR. Adding color to 3D voxel representations improve multi-person tracking. |
|
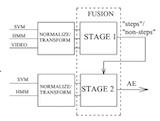
Taras Butko, Andrey Temko, Climent Nadeu, Cristian Canton Interspeech, Brisbane (Australia), 2008. [bibtex] TL;DR. Leveraging spatial information of people in a SmartRoom improves acoustic event detection. |
|
Taras Butko, Andrey Temko, Climent Nadeu, Cristian Canton Workshop on Machine Learning and Multimodal Interaction (MLMI), Utrecht (The Netherlands), 2008. [bibtex] TL;DR. Multimodal data fusion towards acoustic events understanding in SmartRooms. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs Conference on Articulated Motion and Deformable Objects (AMDO), Mallorca (Spain), 2008. [bibtex] TL;DR. New Montecarlo method applied to recover articulated structured (human body) exploiting hierarchies of complexity. |

|
Cristian Canton, Carlos Segura, Montse Pardàs, Josep R. Casas, Javier Hernando IEEE International Conference on Computer Vision and Pattern Recognition (CVPR). Human Communicative Behavior Analysis Workshop, Anchorage (USA), 2008 [bibtex] [poster] TL;DR. Estimate the spatial focus of attention of a group of people leveraging their head orientation. |

|
Ferda Ofli, Cristian Canton, Joelle Tilmanne, Yasemir Demir, Elif Bozkurt, Yucel Yemez, Engin Erzin, Ahmet Murat Tekalp IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas (USA), 2008. [bibtex] TL;DR. Analysis and synthesis of motion patterns correlating audio and multiview information. |

|
Ferda Ofli, Cristian Canton, Joelle Tilmanne, Yasmin Demir, Elif Bozkurt, Yucel Yemez, Engin Erzin, Ahmet Murat Tekalp Journal - EURASIP Journal on Advances on Signal Processing, 2008. [bibtex] TL;DR. Analyze audio to make an avatar dance to the music. |
|
Ferda Ofli, Yasmin Demir, Cristian Canton, Joelle Tilmanne Tilmanne, Korai Balci, Elif Bozkurt, I. Kizoglu, Yucel Yemez, Engin Erzin, Ahmet Murat Tekalp, Lale Akarun, T.A. Erdem IEEE Signal Processing, Communication and Applications Conference, Aydin (Turkey), 2008. [bibtex] TL;DR. Human dance patterns generation directly from music. |
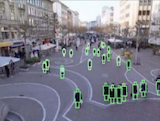
|
István Petrás, Levente Kovács, B. Uğur Töreyin, Csaba Beleznai, Zoltán Szlávik, Uğur Güdükbay, Yiğithan Dedeoğlu, László Havasi, Enis Cetin, Montse Pardàs, Tamás Szirányi, Cristian Canton ACM International Conference on Image and Video Retrieval (CIVR), Amsterdam (The Nederlands), 2007. [bibtex] TL;DR. A system to combine multiple vision signals to detect unusual/outlier behaviors. |
|
|
Cristian Canton, Josep R. Casas, Montse Pardàs Classification of Events, Activities and Relationships Evaluation and Workshop (CLEAR), Baltimore (USA), 2007. [bibtex] TL;DR. Define head templates and use them in a particle filtering context to estimate head position. |
|
|
Cristian Canton, Jordi Salvador, Josep R. Casas Classification of Events, Activities and Relationships Evaluation and Workshop (CLEAR), Baltimore (USA), 2007. [bibtex] TL;DR. Comparison of two tracking aproaches (heuristic vs particle filtering) on the CLEAR dataset. |
|
|
Adolfo López, Cristian Canton, Josep R. Casas IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu (USA), 2007. [bibtex] TL;DR. Person tracking using particle filters directly on voxels, handling multiple objects and delivering high accuracy tracking. |
|
Cristian Canton, Carlos Segura, Josep R. Casas, Montse Pardàs, Javier Hernando Journal - EURASIP Journal on Advances on Signal Processing, 2007. [bibtex] TL;DR. Monte Carlo techniques applied to audiovisual data fusion for head estimation and attention estimation purposes. |

|
Carlos Segura, Cristian Canton, Alberto Abad, Josep R. Casas, Javier Hernando IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Honolulu (USA), 2007. [bibtex] TL;DR. Head pose estimation using both multicamera and microphone arrays signals increase robustness and accuracy of estimation. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs European Signal Processing Conference (EUSIPCO), Florence (Italy), 2006. [bibtex] [slides] TL;DR. Analyze 3D volumes using a human body model to recognize actions in multicamera scenarios. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs, Mehmet Emre Sargin, Ahmet Murat Tekalp, Jornades de Recerca en Automàtica, Visió i Robòtica (AVR), Barcelona (Spain), 2006. [bibtex] TL;DR. Use multiple cameras to create voxels and recognize actions directly from the 3D. |
|
|
Cristian Canton, Josep R. Casas, Montse Pardàs Classification of Events, Activities and Relationships Evaluation and Workshop (CLEAR), Southampton (UK), 2006. [bibtex] TL;DR. Head position estimation using multiview face appearance and its evaluation against the CLEAR dataset. |
|
|
Alberto Abad, Cristian Canton, Carlos Segura, José Luis Landabaso, Dusan Macho, Josep R. Casas, Javier Hernando, Montse Pardàs, Climent Nadeu Classification of Events, Activities and Relationships Evaluation and Workshop (CLEAR), Southampton (UK), 2006. [bibtex] TL;DR. Multiple modalities always improve tracking, specially of humans within a SmartRoom. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs IEEE International Conference on Image Processing (ICIP), Genoa (Italy), 2005. [bibtex] TL;DR. Head orientation estimation by 3D backpropagation of detected skin patches on multiple views. |
|
Cristian Canton, Josep R. Casas, Ahmet Murat Tekalp, Montse Pardàs Workshop on Multimodal Interaction and Related Machine Learning Algorithms (MLMI), Edinburgh (UK), 2005. [bibtex] TL;DR. Kalman filtering of 3D points directly from 2D projections; robust to occlusions by analyzing outliers. Simple yet effective! |

|
Josep R. Casas, Cristian Canton Telecomunications and Electronics Forum Magazine, Technical University of Catalonia, 2005. [bibtex] TL;DR. Multimodal understanding in SmartRooms will enable HCI scenarios to make meetings more effective. |

|
Cristian Canton, Josep R. Casas, Montse Pardàs International Conference on Computer Science (ICCS). Workshop on Computer Graphics and Geometric Modelling, Atlanta (USA), 2005. [bibtex] TL;DR. Tracking multiple 3D points in a multiview scenario using a greedy Bayesian approach. Useful for low compute scenarios and SmartRooms. |
|
Bogdan Smolka, Cristian Canton, Marek Szczepanski, Konrad Wojciechowski International Conference on Computer Vision and Graphics (ICCVG), Zakopane (Poland), 2002. [bibtex] TL;DR. Conductance functions used in anisotropic diffusion schemes may have relevant impact on the final result. |

|
Cristian Canton Technical Report, Technical University of Catalonia, 2003. [bibtex] TL;DR. Use overcomplete representations to represent fingerprints and match them against others. |

|
Bogdan Smolka, Cristian Canton IFAC Workshop on Programable Devices and Systems, Gliwice (Poland), 2001. [bibtex] TL;DR. An old shcool image filtering technique based on the maximization of the similarities between pixels in the filtering window. |

|
Bogdan Smolka, Cristian Canton, Marko Marcevski, Zeina Torbey IFAC Workshop on Programable Devices and Systems, Gliwice (Poland), 2001. [bibtex] TL;DR. When running anisotropic diffusion filters on images, not all conduction functions were born equal. |
|
|
 |
Cristian Canton Technical University of Catalonia, Barcelona (Spain), 2009. [bibtex] [PDF (High Resolution)] TL;DR. Human motion capture using hierarchical models and Monte Carlo optimization techniques. No fancy ML involved, just math and pixels. |
 |
Cristian Canton École Polytechnique Fédérale de Lausanne (EPFL), Lausanne (Switzerland), 2003. [bibtex] TL;DR. Overcomplete representations allow high compression of images/videos. Exploiting texture and edge priors into the process yield to dramatic improvements. |
 |
Cristian Canton, Raquel Tovar Book, USA and Mexico, 2017. [bibtex] TL;DR. Second edition (revised and extended) presenting the biography of Catalan composer Jaime Nunó, composer of Mexico's national anthem. |
 |
Cristian Canton Book - Mozaic Editions and Fondo Nacional para la Cultura y las Artes (FONCA), UK and Mexico, 2012. [bibtex] TL;DR. First critical edition of the complete works of Jaime Nunó (1824-1906) from his manuscripts and first editions. |
 |
Cristian Canton Book - Mozaic Editions and Fondo Nacional para la Cultura y las Artes (FONCA), UK and Mexico, 2011. [bibtex] TL;DR. First biography of Catalan composer Luis G. Jorda (1869-1951) and his trajectory in America and Catalonia during late XIX and early XX centuries. |
 |
Cristian Canton, Raquel Tovar Book - Casa Amèrica-Catalunya, Consulado General de México en Barcelona, Ajuntament de Sant Joan de les Abadesses, Spain, 2010. [bibtex] TL;DR. First biography (in Spanish) of the composer of Mexico's national anthem: the Catalan musician Jaime Nunó (1824-1906). |
 |
Cristian Canton, Raquel Tovar Book - Casa Amèrica-Catalunya, Consulado General de México en Barcelona, Ajuntament de Sant Joan de les Abadesses, Spain, 2010. [bibtex] TL;DR. First biography (in Catalan) of the composer of Mexico's national anthem: the Catalan musician Jaime Nunó (1824-1906). |
 |
Cristian Canton Book - Ajuntament de Les Masies de Roda, Spain, 2010. [bibtex] TL;DR. First biography of Catalan composer Luis G. Jorda (1869-1951) and his trajectory in America and Catalonia during late XIX and early XX centuries. |
 |
Cristian Canton et al. Book - Sextil Editores, Mexico, 2009. [bibtex] TL;DR. An in-depth review of the music in Mexico during the hundreth anniversary of its independence. |
|
Like the style? Shamelessly borrowed from Jon Barron's site. |